Go 语言学习-类型系统
类型系统的概念
类型的定义
一些类型定义的例子(组合类型和基本类型的概念自行百度):
// 下面这些新定义的类型和它们的源类型都是基本类型。
type (
MyInt int
Age int
Text string
)
// 下面这些新定义的类型和它们的源类型都是组合类型。
type IntPtr *int
type Book struct{author, title string; pages int}
type Convert func(in0 int, in1 bool)(out0 int, out1 string)
type StringArray [5]string
type StringSlice []string
func f() {
// 这三个新定义的类型名称只能在此函数内使用。
type PersonAge map[string]int
type MessageQueue chan string
type Reader interface{Read([]byte) int}
}
注意:
- 一个新定义的类型和它的源类型为两个不同的类型。
- 在两个不同的类型定义中的定义的两个类型肯定为两个不同的类型。
- 一个新定义的类型和它的源类型的底层类型一致并且它们的值可以相互显式转换。
- 类型定义可以出现在函数体内。
所以,类型定义和类型别名是有区别的
类型别名声明
可以使用下面的语法来声明自定义类型别名。此语法和类型定义类似,但是请注意每个类型描述中多了一个等号 =。
type (
Name = string
Age = int
)
type table = map[string]int
type Table = map[Name]Age
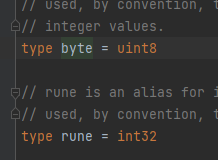
例如 Go 中有两个内置类型别名:byte(类型 uint8 的别名)和 rune(类型 int32 的别名)。
定义类型和非定义类型
一个定义类型是一个在某个类型定义声明中定义的类型。
- 所有的基本类型都是定义类型。
- 一个非定义类型一定是一个组合类型。
在下面的例子中,别名 C 和类型字面表示 []string 都表示同一个非定义类型。 类型 A 和别名 B 均表示同一个定义类型。
type A []string
type B = A
type C = []string
概念:底层类型
在Go中,每个类型都有一个底层类型。规则:
- 一个内置类型的底层类型为它自己。
- 一个组合类型的底层类型为它自己。
- 在一个类型声明中,新声明的类型和源类型共享底层类型。
一个例子:
// 这四个类型的底层类型均为内置类型int。
type (
MyInt int
Age MyInt
)
// 下面这三个新声明的类型的底层类型各不相同。
type (
IntSlice []int // 底层类型为[]int
MyIntSlice []MyInt // 底层类型为[]MyInt
AgeSlice []Age // 底层类型为[]Age
)
// 类型[]Age、Ages和AgeSlice的底层类型均为[]Age。
type Ages AgeSlice
如何溯源一个声明的类型的底层类型?规则很简单,在溯源过程中,当遇到一个内置类型或者非定义类型时,溯源结束。 以上面这几个声明的类型为例,下面是它们的底层类型的溯源过程:

类型转换
类型转换用于将一种数据类型的变量转换为另外一种类型的变量。类型转换基本格式如下:
type_name(expression)
以下实例中将整型转化为浮点型,并计算结果,将结果赋值给浮点型变量:
package main
import "fmt"
func main() {
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
fmt.Printf("mean 的值为: %f\n",mean)
}
使用类型别名是一个很不错的习惯,可以让代码看起来更易懂友好。例如在源码 builtin.go 中可以看到别名的使用, type byte = uint8 byte 是 uint8 的别名; type rune = int32 rune 是 int32 的别名
// 注意别名的正确声明
type MyInt1 int
type MyInt2 = int
func main() {
var i int = 0
var i1 MyInt1 = i // #1
var i2 MyInt2 = i // #2
fmt.Println(i1,i2)
}
编译不通过,MyInt1 是一个新类型,MyInt2 是别名,#1 处类型转换将报错。 可修改为类型装换:
var i1 MyInt1 = MyInt1(i) // #1
“万能” 接口和断言
Go 中的 interface{} 代表任意类型
type Book struct {
auth string
}
func call(arg interface{}) {
fmt.Printf("%v \n", arg)
}
func main() {
call(Book{auth: "张三"})
call(1000)
call("李四")
}
那 interface{} 如何区分传入的类型呢?这时就要使用 Go 的断言了
func call(arg interface{}) {
val, ok := arg.(string)
if !ok {
fmt.Printf("arg is not string type %T \n", arg) // %T 打印某个类型的完整说明
} else {
fmt.Printf("arg is string type %s \n", val)
}
}
func main() {
call(Book{auth: "张三"})
call(1000)
call("李四")
}
打印:
arg is not string type main.Book
arg is not string type int
arg is string type 李四
这个打印的关键字参考 Go 语言中的格式化输出
类型 switch 断言
go 语法种还提供了另外一种类型 switch 的断言方法。
x 断言成了 type 类型,type 类型具体值就是 switch case 的值,如果 x 成功断言成了某个 case 类型,就可以执行那个 case,此时 i := x.(type) 返回的 i 就是那个类型的变量了,可以直接当作 case 类型使用。
switch i := x.(type) {
case nil:
printString("x is nil") // type of i is type of x (interface{})
case int:
printInt(i) // type of i is int
case float64:
printFloat64(i) // type of i is float64
case func(int) float64:
printFunction(i) // type of i is func(int) float64
case bool, string:
printString("type is bool or string") // type of i is type of x (interface{})
default:
printString("don't know the type") // type of i is type of x (interface{})
}
nil 的坑
nil 其实是一个定义好的 变量,来看 builtin 包里面 nil 的定义
// nil is a predeclared identifier representing the zero value for a
// pointer, channel, func, interface, map, or slice type.
var nil Type // Type must be a pointer, channel, func, interface, map, or slice type
// Type is here for the purposes of documentation only. It is a stand-in
// for any Go type, but represents the same type for any given function
// invocation.
type Type int
所以编写以下代码是不会报错的
func main() {
nil := "this is nil"
fmt.Println(nil)
}
打印
this is nil
nil 的默认类型
一般预声明标识符都会有一个默认类型,比如 Go 语言中的 itoa 默认类型就是 int,那么 nil 的默认类型呢?我们写个例子来看一下:
func main() {
const val1 = iota
fmt.Printf("%T\n", val1)
var val2 = nil
fmt.Printf("%T\n", val2)
}
运行结果
# command-line-arguments
./nil.go:10:6: use of untyped nil
在编译时就已经报错,编译器告诉我们使用了无类型的 nil,所以我们可以得出结论:nil 是没有默认类型的,它的类型具有不确定性,我们在使用它时必须要提供足够的信息能够让编译器推断 nil 期望的类型。(nil 是 Go 中唯一一个没有默认类型的类型不确定值)
if nil == nil { // 报错 cannot compare nil == nil (operator == not defined for untyped nil)
}
nil 的比较
nil 的比较我们可以分为以下两种情况:
- nil 标识符的比较
- nil 的值比较
因为 nil 是没有类型的,是在编译期根据上下文确定的,所以要比较 nil 的值也就是比较不同类型的 nil,这又分为同一个类型的 nil 值比较和不同类型 nil 值的比较:
同一个类型的 nil 值比较
// 指针类型的nil比较
fmt.Println((*int64)(nil) == (*int64)(nil))
不同类型的 nil 值比较
// 报错
fmt.Println((*int64)(nil) == (*string)(nil))
空指针是一个没有任何值的指针
func main() {
var a = (*int64)(unsafe.Pointer(uintptr(0x0)))
fmt.Println(a == nil) //true
}
// 运行结果
true
之所以无法比较是因为这些不同的 nil 都尺寸也不同
func main() {
var p *struct{} = nil
fmt.Println( unsafe.Sizeof( p ) ) // 8
var s []int = nil
fmt.Println( unsafe.Sizeof( s ) ) // 24
var m map[int]bool = nil
fmt.Println( unsafe.Sizeof( m ) ) // 8
var c chan string = nil
fmt.Println( unsafe.Sizeof( c ) ) // 8
var f func() = nil
fmt.Println( unsafe.Sizeof( f ) ) // 8
var i interface{} = nil
fmt.Println( unsafe.Sizeof( i ) ) // 16
}
同一个类型的两个 nil 值可能不能相互比较,在Go中,映射类型、切片类型和函数类型是不支持比较类型。 比较同一个不支持比较的类型的两个值(包括nil值)是非法的。 比如,下面的几个比较都编译不通过。
var _ = ([]int)(nil) == ([]int)(nil)
var _ = (map[string]int)(nil) == (map[string]int)(nil)
var _ = (func())(nil) == (func())(nil)
但是,映射类型、切片类型和函数类型的任何值都可以和类型不确定的裸 nil 标识符比较。
// 这几行编译都没问题。
var _ = ([]int)(nil) == nil
var _ = (map[string]int)(nil) == nil
var _ = (func())(nil) == nil
nil 与 interface{}
使用 interface{} 当入参时不能直接判断是否为空
func IsNil(i interface{}) {
if i == nil {
fmt.Println("i is nil")
return
}
fmt.Println("i isn't nil")
}
func main() {
var sl []string
if sl == nil {
fmt.Println("sl is nil")
}
IsNil(sl)
}
实际输出的结果是:
sl is nil
i isn't nil
为啥一个 nil 切片经过空接口 interface{} 一中转,就变成了非 nil。
想要理解这个问题,首先需要理解 interface{} 变量的本质。
Go 语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的空接口 interface{}。
Go 语言使用 runtime.iface 表示带方法的接口,使用 runtime.eface 表示不带任何方法的空接口 interface{}。
一个 interface{} 类型的变量包含了 2 个指针,一个指针指向值的类型,另外一个指针指向实际的值。在 Go 源码中 runtime 包下,我们可以找到 runtime.eface 的定义。
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
从空接口的定义可以看到,当一个空接口变量为 nil 时,需要其两个指针均为 0 才行。
回到最初的问题,我们打印下传入函数中的空接口变量值,来看看它两个指针值的情况。
// InterfaceStruct 定义了一个 interface{} 的内部结构
type InterfaceStruct struct {
pt uintptr // 到值类型的指针
pv uintptr // 到值内容的指针
}
// ToInterfaceStruct 将一个 interface{} 转换为 InterfaceStruct
func ToInterfaceStruct(i interface{}) InterfaceStruct {
return *(*InterfaceStruct)(unsafe.Pointer(&i))
}
func IsNil(i interface{}) {
fmt.Printf("i value is %+v\n", ToInterfaceStruct(i))
}
func main() {
var sl []string
IsNil(sl)
IsNil(nil)
}
运行输出:
i value is {pt:6769760 pv:824635080536}
i value is {pt:0 pv:0}
可见,虽然 sl 是 nil 切片,但是其本上是一个类型为 []string,值为空结构体 slice 的一个变量,所以 sl 传给空接口时是一个非 nil 变量。
再细究的话,你可能会问,既然 sl 是一个有类型有值的切片,为什么又是个 nil。
针对具体类型的变量是否为 nil,不仅仅判断其 Type 是否为 nil,还需要根据其值是否为零值。
因为 sl 一个切片类型,而切片类型的定义在源码包 src/runtime/slice.go 我们可以找到。
type slice struct {
array unsafe.Pointer
len int
cap int
}
我们继续看一下值为 nil 的切片对应的 slice 是否为零值。
func main() {
var sl []string
// 这里没有经过 interface 包装
fmt.Printf("sl value is %+v\n", *(*slice)(unsafe.Pointer(&sl)))
}
运行输出:
sl value is {array:<nil> len:0 cap:0}
不出所料,果然是零值。
至此解释了开篇出乎意料的比较结果背后的原因:空切片为 nil 因为其值为零值,类型为 []string 的空切片传给空接口后,因为空接口的值并不是零值,所以接口变量不是 nil。
所以根本原因是 因为 interface{} 不是空的
所以如果要判断是否为空,需要使用反射
func main() {
test((*B)(nil))
}
func test(target interface{}) {
fmt.Println(reflect.ValueOf(target).IsNil())
}
输出:
true
两个 interface 可以比较吗?
在Go语言中,两个接口类型是可以进行比较的。接口比较的规则是:只有两个接口的动态类型和动态值都相同,它们才被认为是相等的。
以下是一个比较接口的示例:
package main
import "fmt"
type Shape interface {
Area() float64
}
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return 3.14 * c.Radius * c.Radius
}
func main() {
shape1 := Circle{Radius: 5}
shape2 := Circle{Radius: 5}
var shapeInterface1 Shape = shape1
var shapeInterface2 Shape = shape2
fmt.Println(shapeInterface1 == shapeInterface2) // true
}
在上述示例中,我们定义了一个 Shape 接口和一个 Circle 结构体,Circle 结构体实现了 Shape 接口的 Area() 方法。然后,我们创建了两个 Circle 结构体实例 shape1 和 shape2,并将它们赋值给相应的接口变量 shapeInterface1 和 shapeInterface2。
通过比较 shapeInterface1 和 shapeInterface2,我们可以看到它们的比较结果为 true,因为它们的动态类型和动态值都相同。换句话说,它们实际上引用了相同类型的对象。
需要注意的是,当比较接口时,只有在两个接口的动态类型和动态值都相等的情况下,它们才会被认为是相等的。如果接口中的动态类型或动态值有任何差异,它们将被认为是不相等的。
隐式转换的坑
刷这道 NC52 有效括号序列 时遇到一个坑,下面那个 list 插入字符类型时 stack.PushBack(')') ,这个 ')' 被隐式转换成了 int32 类型,不能直接和 byte 类型比较(int8),所以需要转成 int32 才能比较
func isValid(s string) bool {
arr := []byte(s)
stack := list.New()
for _, v := range arr {
if v == '(' {
stack.PushBack(')')
} else if v == '{' {
stack.PushBack('}')
} else if v == '[' {
stack.PushBack(']')
} else if stack.Len() == 0 || stack.Remove(stack.Back()) != int32(v) {
return false
}
}
return stack.Len() == 0
}
String 类型
string 类型的指针使用
需要注意的是,在一般情况下,直接使用字符串字面量或字符串变量进行赋值和操作是更常见和简洁的方式。只有在特定的需求下,才需要使用 new 函数来分配 string 类型的内存。
然而,有一些特定的场景可能会使用 new 函数来分配 string 类型的内存,例如:
动态构建字符串:如果需要动态构建字符串,将多个字符串片段拼接在一起,可以使用 strings.Builder 或 bytes.Buffer 来高效地构建字符串。这些类型提供了缓冲区来减少内存分配和复制,以提高性能。在这种情况下,new 函数可能会与 strings.Builder 或 bytes.Buffer 结合使用,用于创建存储结果字符串的指针。
封装字符串处理逻辑:有时候,我们可能会将字符串处理逻辑封装在一个自定义类型中,并且需要使用 new 分配内存来创建该自定义类型的实例。这种情况下,自定义类型可能会包含一个或多个字符串字段,因此需要使用 new 来分配内存并初始化这些字段。
需要注意的是,在一般情况下,直接使用字符串字面量或字符串变量进行赋值和操作是更常见和简洁的方式。只有在特定的需求下,才需要使用 new 函数来分配 string 类型的内存。
以下是一个示例,演示了如何使用 new 函数分配 string 类型内存的情况:
package main
import (
"fmt"
"strings"
)
type CustomString struct {
Value *string
}
func main() {
// 封装字符串处理逻辑
customStr := CustomString{
Value: new(string),
}
*customStr.Value = "Hello, Gopher!"
fmt.Println(*customStr.Value)
// 动态构建字符串
builder := new(strings.Builder)
builder.WriteString("Hello, ")
builder.WriteString("World!")
result := builder.String()
fmt.Println(result)
}
可以用反射修改字符串吗?
在 Go 中,字符串是不可变的,这意味着不能直接使用反射修改字符串的内容。字符串的值在创建后就无法更改。
在 Go 中,字符串是以字节数组(byte array)的形式存储的,存储在堆上,而字符串本身是一个只读的数据结构。
反射(reflection)是 Go 语言提供的一种机制,用于在运行时检查变量的类型信息并对其进行操作。虽然反射可以用于修改某些可变类型的值,但对于字符串,反射并不能修改其内容。
以下是一个示例代码,展示了使用反射尝试修改字符串的情况:
package main
import (
"fmt"
"reflect"
)
func main() {
str := "Hello, World!"
fmt.Println("Original:", str)
value := reflect.ValueOf(&str).Elem()
value.SetString("Modified!")
fmt.Println("Modified:", str)
}
在上述示例中,我们尝试使用反射修改字符串的内容。首先,我们通过 reflect.ValueOf 将字符串 str 的地址传递给 reflect.Value。然后,我们使用 SetValue 方法尝试修改字符串的值为 "Modified!"。
然而,当我们运行该示例时,会遇到运行时错误:
panic: reflect.Value.SetString using unaddressable value
这是因为字符串是不可变的,它的底层字节数组是只读的,因此无法通过反射修改字符串的内容。尽管可以通过反射更改字符串变量本身的值(例如修改变量指向的字符串地址),但不能修改字符串的实际内容。
总结起来,反射不能直接用于修改字符串的内容,因为字符串是不可变的。如果需要对字符串进行修改操作,可以考虑将字符串转换为可变类型(如字节数组),对其进行修改,然后再转换回字符串。但需要注意,这种方式会涉及到内存分配和复制的开销,因此在性能敏感的场景中应慎重使用。
字符串是如何保证只读的
在 Go 中,字符串的只读性是通过语言的设计和实现来保证的。下面是一些机制和策略,用于确保字符串的只读性:
字符串不可修改:一旦字符串被创建,其内容就无法被修改。这意味着无法通过索引或指针来直接修改字符串中的字符。任何对字符串的修改操作都会创建一个新的字符串,而不会修改原始字符串的内容。
字符串赋值的复制:在将一个字符串赋值给另一个字符串变量时,实际上是将底层的字节数组的指针和长度信息复制到新的变量中。这样,两个字符串变量将引用相同的字节数组,但是它们是独立的,修改其中一个变量的内容不会影响另一个变量。
字符串字节数组的只读性:字符串的底层字节数组是只读的。这意味着字符串变量本身是只读的,无法通过任何手段来直接修改其底层字节数组的内容。
垃圾回收:Go 的垃圾回收器负责管理字符串的内存,当字符串不再被引用时,垃圾回收器会自动回收其所占用的内存空间。这确保了字符串的安全性和内存管理的有效性。
通过这些机制和策略,Go 保证了字符串的只读性。这使得字符串在并发环境中更容易共享和使用,并提供了更高的安全性和可预测性。开发人员无需担心字符串被意外修改,同时也不需要为字符串的复制和管理分配额外的资源。
什么是 rune 类型?
rune 是Go语言中的内置类型之一,它是一个别名类型,对应于 int32 类型。它用于表示 Unicode 码点(Unicode code point),也可以理解为表示 Unicode 字符的整数值。
在Go语言中,rune 类型主要用于处理 Unicode 字符,特别是处理多字节字符和字符串的情况。它提供了一种简便的方式来处理 Unicode 字符,使得在字符串操作、字符编码转换和文本处理方面更加方便和统一。
以下是一个使用 rune 类型的简单示例:
package main
import "fmt"
func main() {
str := "Hello, 世界"
// 遍历字符串并打印每个字符的 Unicode 码点
for _, char := range str {
fmt.Printf("%c - %U\n", char, char)
}
}
在上述示例中,我们定义了一个包含英文和中文字符的字符串 str。通过使用 range 迭代字符串,我们可以逐个访问其中的字符,每个字符的类型是 rune。我们使用 %c 格式化符号打印字符本身,并使用 %U 格式化符号打印字符的 Unicode 码点。
运行上述示例,可能会得到类似以下的输出:
H - U+0048
e - U+0065
l - U+006C
l - U+006C
o - U+006F
, - U+002C
- U+0020
世 - U+4E16
界 - U+754C
这个示例展示了 rune 类型的使用,它使我们能够处理多字节字符和 Unicode 字符串,并以统一的方式处理和操作其中的字符。